在前面的文章中介绍了`MNN`以及`OpenCV`的交叉编译,本篇文章将基于这两个库完成人脸检测。人脸检测(Face Detection),就是给一幅图像,找出图像中的所有人脸位置,通常用一个矩形框框起来。传统的人脸检测,通常使用`Haar`特征可以快速的检测人脸,在OpenCV中可以通过`CascadeClassifier`函数使用此分类器。然而在VisionFive中,`CascadeClassifier`检测效率并不高,在这里本文使用[Ultra-Light-Fast-Generic-Face-Detector-1MB](https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB) 简称(Ultra)模型对人脸进行检测。Ultra模型是针对边缘计算设备设计的轻量人脸检测模型,模型较小,同时计算速度快。

代码时间
1. 设置编译器
$ export PATH=$PATH:${YOUR_PATH}/riscv/bin$ export CC=riscv64-unknown-linux-gnu-gcc$ export CXX=riscv64-unknown-linux-gnu-g++2. 模型部分
MNN的使用较为简单,使用方法类似TensorFlow 1.x,简要的流程为
// 创建会话createSession();// 设置输入getSessionInput();// 运行会话runSession();// 获取输出getSessionOutput();在该逻辑下,将模型的运行预处理,推理,后处理封装为一个模块:
// ultraFace.hpp#ifndef UltraFace_hpp#define UltraFace_hpp#pragma once#include "MNN/Interpreter.hpp"#include "MNN/MNNDefine.h"#include "MNN/Tensor.hpp"#include "MNN/ImageProcess.hpp"#include <opencv2/opencv.hpp>#include <algorithm>#include <iostream>#include <string>#include <vector>#include <memory>#include <chrono>#define num_featuremap 4#define hard_nms 1#define blending_nms 2 /* mix nms was been proposaled in paper blaze face, aims to minimize the temporal jitter*/typedef struct FaceInfo { float x1; float y1; float x2; float y2; float score;} FaceInfo;class UltraFace {public: UltraFace(const std::string &mnn_path, int input_width, int input_length, int num_thread_ = 4, float score_threshold_ = 0.7, float iou_threshold_ = 0.3, int topk_ = -1); ~UltraFace(); int detect(cv::Mat &img, std::vector<FaceInfo> &face_list);private: void generateBBox(std::vector<FaceInfo> &bbox_collection, MNN::Tensor *scores, MNN::Tensor *boxes); void nms(std::vector<FaceInfo> &input, std::vector<FaceInfo> &output, int type = blending_nms);private: std::shared_ptr<MNN::Interpreter> ultraface_interpreter; MNN::Session *ultraface_session = nullptr; MNN::Tensor *input_tensor = nullptr; int num_thread; int image_w; int image_h; int in_w; int in_h; int num_anchors; float score_threshold; float iou_threshold; const float mean_vals[3] = {127, 127, 127}; const float norm_vals[3] = {1.0 / 128, 1.0 / 128, 1.0 / 128}; const float center_variance = 0.1; const float size_variance = 0.2; const std::vector<std::vector<float>> min_boxes = { {10.0f, 16.0f, 24.0f}, {32.0f, 48.0f}, {64.0f, 96.0f}, {128.0f, 192.0f, 256.0f}}; const std::vector<float> strides = {8.0, 16.0, 32.0, 64.0}; std::vector<std::vector<float>> featuremap_size; std::vector<std::vector<float>> shrinkage_size; std::vector<int> w_h_list; std::vector<std::vector<float>> priors = {};};#endif /* UltraFace_hpp */// ultraFace.cpp#define clip(x, y) (x < 0 ? 0 : (x > y ? y : x))#include "UltraFace.hpp"using namespace std;UltraFace::UltraFace(const std::string &mnn_path, int input_width, int input_length, int num_thread_, float score_threshold_, float iou_threshold_, int topk_) { num_thread = num_thread_; score_threshold = score_threshold_; iou_threshold = iou_threshold_; in_w = input_width; in_h = input_length; w_h_list = {in_w, in_h}; for (auto size : w_h_list) { std::vector<float> fm_item; for (float stride : strides) { fm_item.push_back(ceil(size / stride)); } featuremap_size.push_back(fm_item); } for (auto size : w_h_list) { shrinkage_size.push_back(strides); } /* generate prior anchors */ for (int index = 0; index < num_featuremap; index++) { float scale_w = in_w / shrinkage_size[0][index]; float scale_h = in_h / shrinkage_size[1][index]; for (int j = 0; j < featuremap_size[1][index]; j++) { for (int i = 0; i < featuremap_size[0][index]; i++) { float x_center = (i + 0.5) / scale_w; float y_center = (j + 0.5) / scale_h; for (float k : min_boxes[index]) { float w = k / in_w; float h = k / in_h; priors.push_back({clip(x_center, 1), clip(y_center, 1), clip(w, 1), clip(h, 1)}); } } } } /* generate prior anchors finished */ num_anchors = priors.size(); ultraface_interpreter = std::shared_ptr<MNN::Interpreter>(MNN::Interpreter::createFromFile(mnn_path.c_str())); MNN::ScheduleConfig config; config.numThread = num_thread; MNN::BackendConfig backendConfig; backendConfig.precision = (MNN::BackendConfig::PrecisionMode) 2; config.backendConfig = &backendConfig; ultraface_session = ultraface_interpreter->createSession(config); input_tensor = ultraface_interpreter->getSessionInput(ultraface_session, nullptr);}UltraFace::~UltraFace() { ultraface_interpreter->releaseModel(); ultraface_interpreter->releaseSession(ultraface_session);}int UltraFace::detect(cv::Mat &raw_image, std::vector<FaceInfo> &face_list) { if (raw_image.empty()) { std::cout << "image is empty ,please check!" << std::endl; return -1; } image_h = raw_image.rows; image_w = raw_image.cols; cv::Mat image; cv::resize(raw_image, image, cv::Size(in_w, in_h)); ultraface_interpreter->resizeTensor(input_tensor, {1, 3, in_h, in_w}); ultraface_interpreter->resizeSession(ultraface_session); std::shared_ptr<MNN::CV::ImageProcess> pretreat( MNN::CV::ImageProcess::create(MNN::CV::BGR, MNN::CV::RGB, mean_vals, 3, norm_vals, 3)); pretreat->convert(image.data, in_w, in_h, image.step[0], input_tensor); auto start = chrono::steady_clock::now(); // run network ultraface_interpreter->runSession(ultraface_session); // get output data string scores = "scores"; string boxes = "boxes"; MNN::Tensor *tensor_scores = ultraface_interpreter->getSessionOutput(ultraface_session, scores.c_str()); MNN::Tensor *tensor_boxes = ultraface_interpreter->getSessionOutput(ultraface_session, boxes.c_str()); MNN::Tensor tensor_scores_host(tensor_scores, tensor_scores->getDimensionType()); tensor_scores->copyToHostTensor(&tensor_scores_host); MNN::Tensor tensor_boxes_host(tensor_boxes, tensor_boxes->getDimensionType()); tensor_boxes->copyToHostTensor(&tensor_boxes_host); std::vector<FaceInfo> bbox_collection; auto end = chrono::steady_clock::now(); chrono::duration<double> elapsed = end - start; cout << "inference time:" << elapsed.count() << " s" << endl; generateBBox(bbox_collection, tensor_scores, tensor_boxes); nms(bbox_collection, face_list); return 0;}void UltraFace::generateBBox(std::vector<FaceInfo> &bbox_collection, MNN::Tensor *scores, MNN::Tensor *boxes) { for (int i = 0; i < num_anchors; i++) { if (scores->host<float>()[i * 2 + 1] > score_threshold) { FaceInfo rects; float x_center = boxes->host<float>()[i * 4] * center_variance * priors[i][2] + priors[i][0]; float y_center = boxes->host<float>()[i * 4 + 1] * center_variance * priors[i][3] + priors[i][1]; float w = exp(boxes->host<float>()[i * 4 + 2] * size_variance) * priors[i][2]; float h = exp(boxes->host<float>()[i * 4 + 3] * size_variance) * priors[i][3]; rects.x1 = clip(x_center - w / 2.0, 1) * image_w; rects.y1 = clip(y_center - h / 2.0, 1) * image_h; rects.x2 = clip(x_center + w / 2.0, 1) * image_w; rects.y2 = clip(y_center + h / 2.0, 1) * image_h; rects.score = clip(scores->host<float>()[i * 2 + 1], 1); bbox_collection.push_back(rects); } }}void UltraFace::nms(std::vector<FaceInfo> &input, std::vector<FaceInfo> &output, int type) { std::sort(input.begin(), input.end(), [](const FaceInfo &a, const FaceInfo &b) { return a.score > b.score; }); int box_num = input.size(); std::vector<int> merged(box_num, 0); for (int i = 0; i < box_num; i++) { if (merged[i]) continue; std::vector<FaceInfo> buf; buf.push_back(input[i]); merged[i] = 1; float h0 = input[i].y2 - input[i].y1 + 1; float w0 = input[i].x2 - input[i].x1 + 1; float area0 = h0 * w0; for (int j = i + 1; j < box_num; j++) { if (merged[j]) continue; float inner_x0 = input[i].x1 > input[j].x1 ? input[i].x1 : input[j].x1; float inner_y0 = input[i].y1 > input[j].y1 ? input[i].y1 : input[j].y1; float inner_x1 = input[i].x2 < input[j].x2 ? input[i].x2 : input[j].x2; float inner_y1 = input[i].y2 < input[j].y2 ? input[i].y2 : input[j].y2; float inner_h = inner_y1 - inner_y0 + 1; float inner_w = inner_x1 - inner_x0 + 1; if (inner_h <= 0 || inner_w <= 0) continue; float inner_area = inner_h * inner_w; float h1 = input[j].y2 - input[j].y1 + 1; float w1 = input[j].x2 - input[j].x1 + 1; float area1 = h1 * w1; float score; score = inner_area / (area0 + area1 - inner_area); if (score > iou_threshold) { merged[j] = 1; buf.push_back(input[j]); } } switch (type) { case hard_nms: { output.push_back(buf[0]); break; } case blending_nms: { float total = 0; for (int i = 0; i < buf.size(); i++) { total += exp(buf[i].score); } FaceInfo rects; memset(&rects, 0, sizeof(rects)); for (int i = 0; i < buf.size(); i++) { float rate = exp(buf[i].score) / total; rects.x1 += buf[i].x1 * rate; rects.y1 += buf[i].y1 * rate; rects.x2 += buf[i].x2 * rate; rects.y2 += buf[i].y2 * rate; rects.score += buf[i].score * rate; } output.push_back(rects); break; } default: { printf("wrong type of nms."); exit(-1); } } }}使用detect接口即可轻松获得输入图片中所有被检测脸的检测框
#include "UltraFace.hpp"#include <iostream>#include <opencv2/opencv.hpp>using namespace std;int main(int argc, char **argv) { if (argc <= 2) { fprintf(stderr, "Usage: %s <mnn .mnn> [image files...]\n", argv[0]); return 1; } string mnn_path = argv[1]; UltraFace ultraface(mnn_path, 320, 240, 4, 0.65); // config model input for (int i = 2; i < argc; i++) { string image_file = argv[i]; cout << "Processing " << image_file << endl; cv::Mat frame = cv::imread(image_file); auto start = chrono::steady_clock::now(); vector<FaceInfo> face_info; ultraface.detect(frame, face_info); auto end = chrono::steady_clock::now(); for (auto face : face_info) { cv::Point pt1(face.x1, face.y1); cv::Point pt2(face.x2, face.y2); cv::rectangle(frame, pt1, pt2, cv::Scalar(0, 255, 0), 2); } chrono::duration<double> elapsed = end - start; cout << "all time: " << elapsed.count() << " s" << endl; // cv::imshow("UltraFace", frame); // cv::waitKey(); string result_name = "result" + to_string(i) + ".jpg"; cv::imwrite(result_name, frame); } return 0;}运行结果
编译运行
$ cmake -Bbuild -S .$ cmake --build build检测时间及检测效果如下:
user@starfive:~/Documents/u_face_bin$ sudo ./u_face_detect ./assets/slim/slim-320.mnn 3.bmpThe device support i8sdot:0, support fp16:0, support i8mm: 0Processing 3.bmpinference time:0.055068 sall time: 0.0691885 s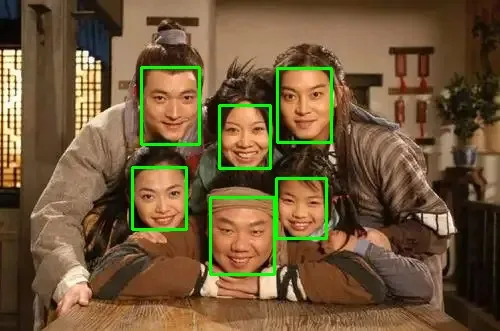
当然还可以检测视频中人脸,视频链接见下
