同构融合技术
为了加速AI计算,芯片企业设计了多种专用处理器架构,如GPGPU、NPU、TPU等。这些专用处理器架构在执行调度代码及应用层代码时,需要主控CPU的配合,如下图所示。因此,通常需要构建复杂的异构调度系统来协调CPU和XPU的额外数据交互和同步。
进迭时空践行的同构融合技术,创新性地在CPU内集成TensorCore,以RISC-V指令集为统一的软硬件接口,驱动Scalar标量算力、Vector向量算力和 Matrix AI算力,支持软件和AI模型同时在RISC-V AI核上运行,并通过程序正常跳转实现软件和AI模型之间的事件和数据交互,进而完成整个AI应用执行。我们将这种使用同构融合技术,得到具有AI算力的CPU称为AI CPU。
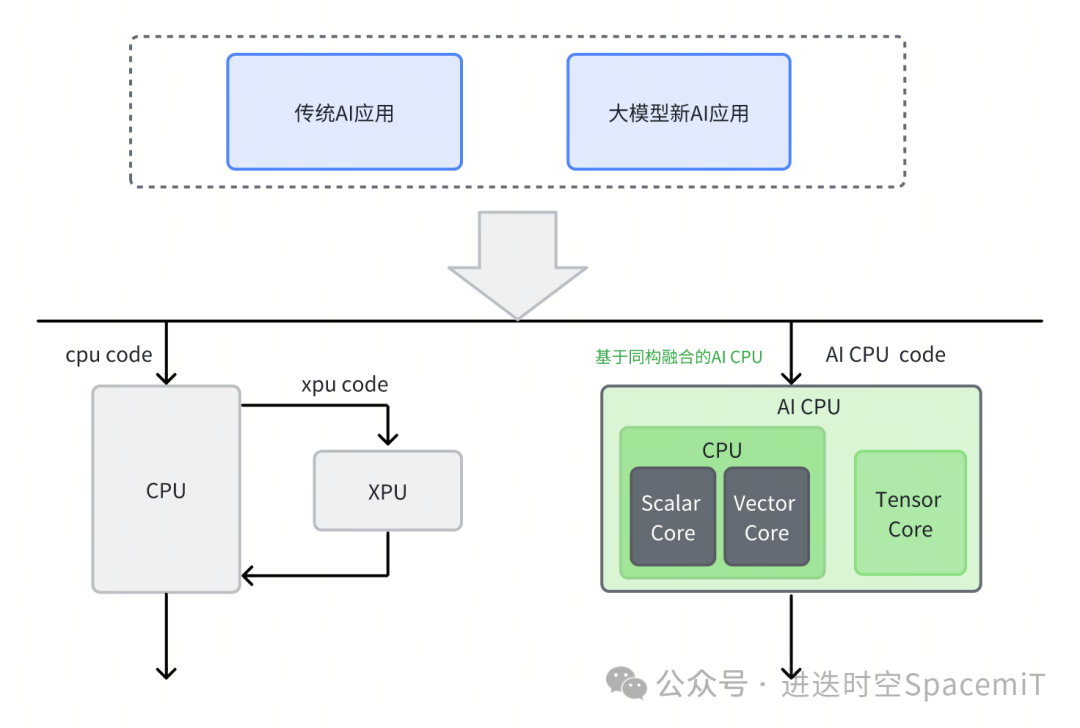
同构融合技术以更轻的软件基础设施构建接近Nvidia的软件层级
虽然市面上已有多种不同架构且硬件做的非常出色的AI加速器,但是除了AIOT细分场景之外,Nvidia占据了AI计算绝大多数市场份额,成为AI计算主流架构,并深刻影响工业界学术界AI计算的发展。Nvidia通过CUDA将异构开发的门槛降至最低,并基于多层级的软件栈构建了护城河。基于这些软件栈,全球开发者都在壮大Nvidia生态。很多企业的GPGPU发展策略是硬件上学习Nvidia,软件上兼容CUDA生态。由于很难跟上Nvidia的快速迭代,这条路径并不容易实现。
同构融合有望成为新的发展路径。相比于异构加速器和CPU的组合,同构融合技术在硬件层面上对AI算力和通用CPU进行了更高层次的封装,用户不需要关心主控CPU和异构加速器之间的数据同步,并且保留了通用CPU的调试和开发方式。厂商不需要开发复杂的异构调度系统,也不需要开发额外的驱动管理就可以让开发者便捷的使用AI算力。另外,同构融合技术中CPU的通用性和RISC-V架构良好的开源生态基础,进一步降低了需要自建软件栈的复杂度。
综上,进迭时空基于开源软件生态,以更轻的基础软件设施,构建了接近Nvidia的软件层级,如下图所示。我们的目标是,基于这些软件层级,达到接近Nvidia的AI通用性。
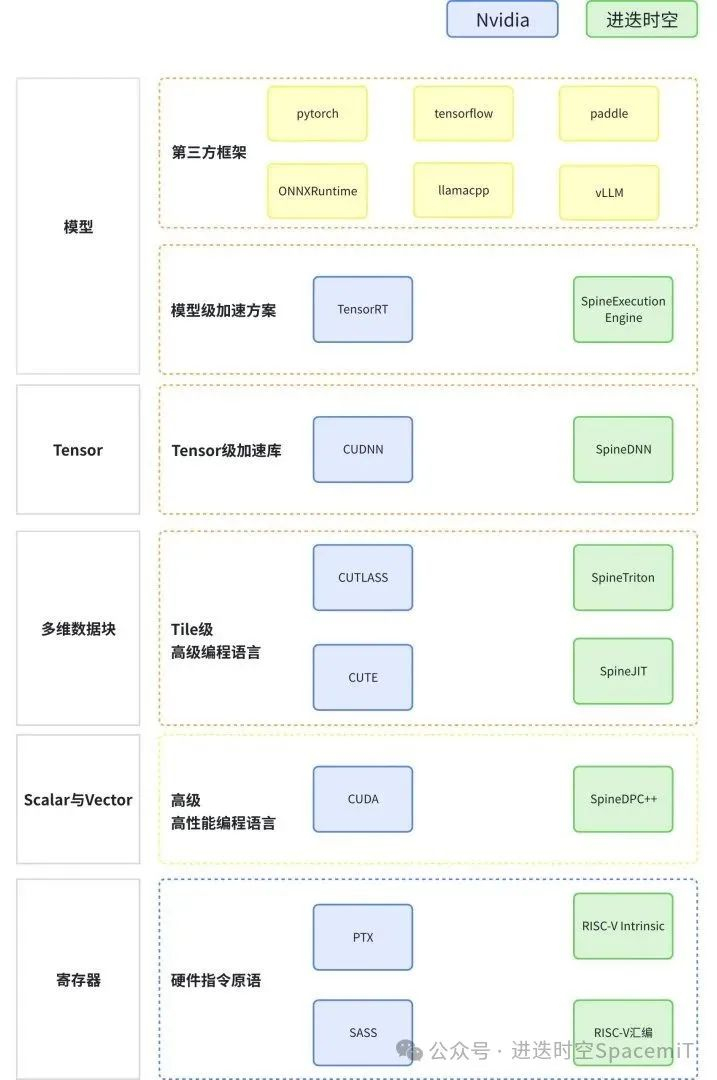
01 在模型加速层面,与Nvidia一样,进迭时空的推理引擎可以非常便捷的接入各主流第三方框架
02 在Tensor及多维数据块层面,SpineDNN、SpineTriton及SpineJit分别对标CUDNN、CUTLASS及CUTE
03 在Scalar及Vector层面,SpineDPC++可以对标CUDA
04 最底层的寄存器层面,标准的Intrinsic接口则对标Nvidia的PTX接口
进迭时空同构融合技术实践
进迭时空基于同构融合技术完成两代通用RISC-V AI核的研发。
第一代RISC-V AI核A60实现2Tops算力,支持INT8等数据格式。A60核已经应用于RISC-V AI CPU芯片K1,实践表明,同构融合AI算力可以无缝运行所有AI算法,更安全地加速从TEE到REE所有AI应用。RISC-V AI CPU芯片K1也是第一个完整提供Scalar、Vector和Matrix三个维度关键算力的RISC-V芯片。在运行常见的AI算法时,K1的实际性能是传统芯片的3-5倍,某些AI应用帧率提升可达10倍以上。
尤其是在运行大模型算法时,Matrix算力可以从容应对prefill阶段的算力需求,CPU出色的访存系统可以解决decode阶段的带宽需求,无需构建复杂的异构计算调度系统。此外,由于CPU的通用性,可以支持几乎所有低bit量化方式,将带宽需求降至最低。
更重要的是,将整个AI应用涉及的计算步骤全部迁移至AI CPU上,还可以为客户提供更加简单高效的开发方式。不仅能够避免在多个硬件设备上开发和调试,而且在一个编程模型覆盖AI开发全过程,能够让部署和调试变得轻松,让算法快速实现价值。例如,K1芯片在客户场景下,可以把在传统NPU上适配新算法所需的3-6个月时间压缩到1周以内,K1芯片已支持多个客户在语音和机器视觉领域快速开发了基于最新AI大模型的产品。
第二代RISC-V AI核A100已经研发完毕,预期无论在大模型运行效率方面,还是运行传统AI效率方面都能达到业界先进水平。
此外在算力堆叠方面,同构融合技术路线通过采用Core-to-Core coherence和Cluster-to-Cluster coherence,能以与GPU相同的技术实现多芯片级联和算力堆叠。与总线的Die2Die一致性技术结合后,通往多芯片算力堆叠的规模有望接近现有最先进GPU集群。
同构融合技术适合运行MoE大模型
MOE模型(Mixture of Experts,混合专家模型)是一种基于分而治之策略的神经网络架构,它将复杂的问题分解为多个子问题,每个子问题由一个独立的模型(称为专家)进行处理。MOE模型在单请求推理场景,每个token只需要使用部分专家参与计算。这些专家共同组成了MOE模型的激活参数。以DeepSeek-R1模型为例,671B的模型,只有37B的激活参数。对于FP8的模型,相当于需要将近700GB的容量来存放模型所有的权重,但是在进行单请求推理时,每个token只需要使用将近40GB的权重。相比于Dense模型,MOE模型是一个大容量,弱带宽的推理需求。相较于GDDR和HBM,内存容量更容易扩展;再加上专家的选择是动态的,其计算和访存模式是CPU极其擅长的。
GPU与NPU适合密集的重复计算模式,而CPU适合复杂调度场景下的计算模式,AI CPU介于两者之间。MoE的兴起,代表了一个兼具大容量与复杂逻辑的大模型发展趋势,而这正是AI CPU的发力场景。
想要了解及购买进迭时空产品,请前往iCEasy商城品牌专区:
https://s.iceasy.com/1Pjqx1
iCEasy商城欢迎您的到来!