随着 AI 使用场景不断扩展(从文档摘要到定制化软件代理),开发者和技术爱好者正在寻求以更 快、更灵活的方式来运行大语言模型(LLM)。
在配备 NVIDIA GeForce RTX GPU 的 PC 上本地运行模型,可实现高性能推理、增强型数据隐私保护,以及对 AI 部署与集成的完全控制。LM Studio 等工具(可免费试用)使这一切成为可能,为用户提供了在自有硬件上探索和构建 LLM 的便捷途径。
LM Studio 已成为最主流的本地 LLM 推理工具之一。该应用基于高性能 llama.cpp 运行时构建,支持完全离线运行模型,还可作为兼容 OpenAI 应用编程接口(API)的端点,无缝集成至定制化工作流程。
得益于 CUDA 12.8,LM Studio 0.3.15 的推出提升了 RTX GPU 的性能,模型加载和响应时间均有显著改善。此次更新还推出数项面向开发者的全新功能,包括通过“tool_choice”参数增强工具调用能力和重新设计的系统提示词编辑器。
LM Studio 的最新改进提高了它的性能和易用性——实现了 RTX AI PC 上迄今最高的吞吐量。这意味着更快的响应速度、更敏捷的交互体验,以及更强大的本地 AI 构建与集成工具。
日常 App 与 AI 加速相遇
LM Studio 专为灵活性打造 —— 既适用于随意的实验,也可完全集成至定制化工作流。用户可以通过桌面聊天界面与模型交互,或启用开发者模式部署兼容 OpenAI API 的端点。这使得将本地大语言模型连接到 VS Code 等应用的工作流或定制化桌面智能体变得轻而易举。
例如,LM Studio 可以与 Obsidian 集成,后者是一款广受欢迎的 Markdown 知识管理应用。使用 Text Generator 和 Smart Connections 等社区开发的插件,用户可以生成内容、对研究进行摘要并查询自己的笔记 —— 所有功能均由基于 LM Studio 运行的本地大语言模型提供支持。这些插件直接连接到 LM Studio 的本地服务器,无需依赖云服务即可实现快速且私密的 AI 交互。
 使用 LM Studio 生成由 RTX 加速的笔记的示例
使用 LM Studio 生成由 RTX 加速的笔记的示例
0.3.15 更新新增多项开发者功能,包括通过“tool_choice”参数实现更细粒度的工具控制,以及经过升级、支持更长或更复杂提示词的系统提示词编辑器。
tool_choice 参数使开发者能够控制模型与外部工具的交互方式 —— 无论是强制调用工具、完全禁用工具,还是允许模型动态决策。这种增强的灵活性对于构建结构化交互、检索增强生成(RAG)工作流或智能体工作流尤为重要。这些更新共同增强了开发者基于大语言模型开展实验和生产用途两方面的能力。
LM Studio 支持广泛的开源模型(包括 Gemma、Llama 3、Mistral 和 Orca),支持从 4 位到全精度的各种量化格式。
常见场景涵盖 RAG、长上下文窗口多轮对话、基于文档的问答和本地智能体工作流。而 NVIDIA RTX 加速的 llama.cpp 软件库可以作为本地推理服务器,让 RTX AI PC 用户轻松利用本地大语言模型。
无论是为紧凑型 RTX 设备实现能效优化,还是在高性能台式机上更大限度地提高吞吐量,LM Studio 能够在 RTX 平台上提供从全面控制、速度到隐私保障的一切。
体验 RTX GPU 的最大吞吐量
LM Studio 加速的核心在于 llama.cpp —— 这是一款专为基于消费级硬件进行高效推理而设计的开源运行时。NVIDIA 与 LM Studio 和 llama.cpp 社区展开合作,集成多项增强功能,以尽可能充分地发挥 RTX GPU 的性能。
关键优化包括:
· CUDA 计算图优化:将多个 GPU 操作聚合为单次 CPU 调用,从而降低 CPU 负载并可将模型吞吐量提高最多达 35%。
· Flash Attention CUDA 内核:通过改进大语言模型的注意力处理机制(Transformer 模型的核心运算),实现吞吐量额外提升 15%。这可以在不增加显存或算力需求的前提下,支持更长的上下文窗口。
· 支持最新 RTX 架构:LM Studio 升级至 CUDA 12.8 版本,确保全面兼容从 GeForce RTX 20 系列到 NVIDIA Blackwell 架构 GPU 的全部 RTX AI PC 设备,使用户能够灵活扩展其本地 AI 工作流 —— 从笔记本电脑到高端台式机。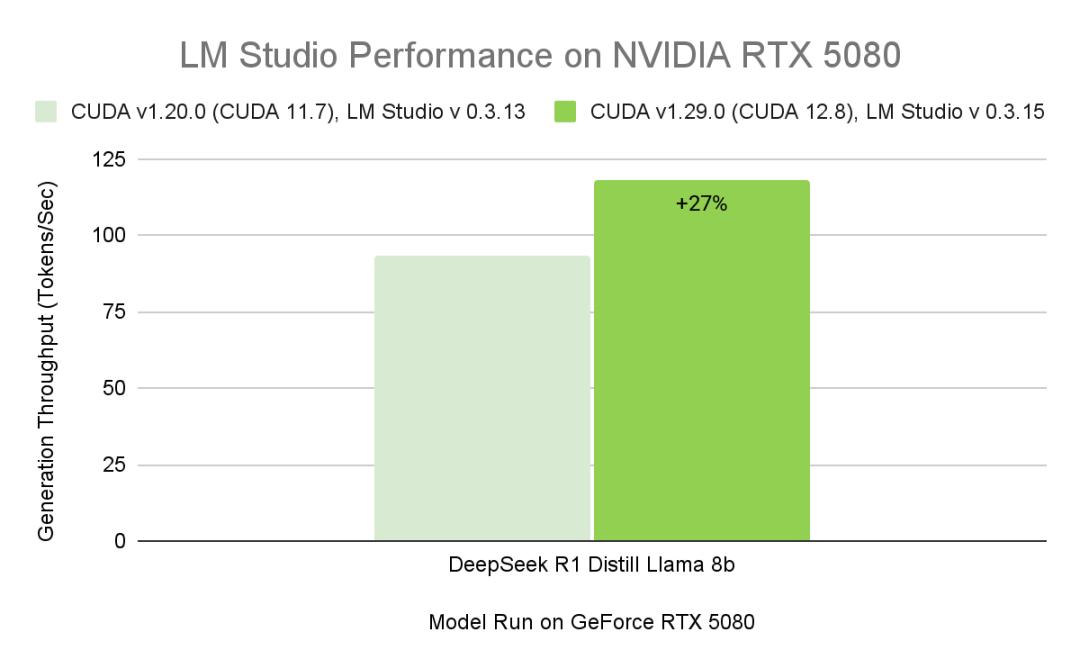
数据展示了不同版本的 LM Studio 和 CUDA 后端在 GeForce RTX 5080 上运行 DeepSeek-R1-Distill-Llama-8B 模型的性能数据。所有配置均使用 Q4_K_M GGUF(Int4)量化,在 BS=1、ISL=4000、OSL=200 并开启 Flash Attention 的条件下测量。得益于 NVIDIA 对 llama.cpp 推理后端的贡献,CUDA 计算图在最新版本的 LM Studio 中实现了约 27% 的加速。
借助兼容的驱动,LM Studio 可自动升级到 CUDA 12.8 运行时,从而显著缩短模型加载时间并提高整体性能。
这些增强功能显著提升了所有 RTX AI PC 设备的推理流畅度与响应速度 —— 从轻薄笔记本到高性能台式机与工作站。
LM Studio 使用入门
LM Studio 提供免费下载,支持 Windows、macOS 和 Linux 系统。借助最新的 0.3.15 版本以及持续优化,用户将在性能、定制化与易用性方面得到持续提升 —— 让本地 AI 更快、更灵活、更易用。
用户既能通过桌面聊天界面加载模型,也可以启用开发者模式,开放兼容 OpenAI API 的接口。
要快速入门,请下载最新版本的 LM Studio 并打开应用。
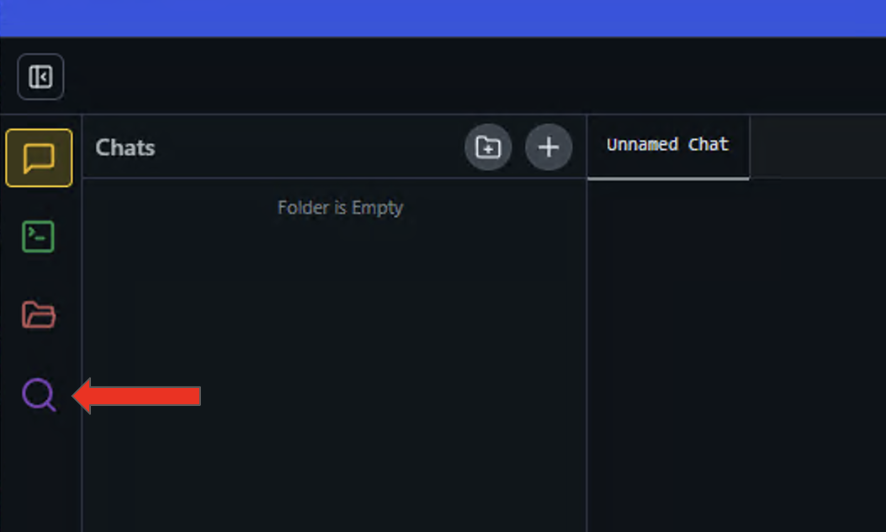
1、点击左侧面板上的放大镜图标以打开 Discover(发现)菜单。
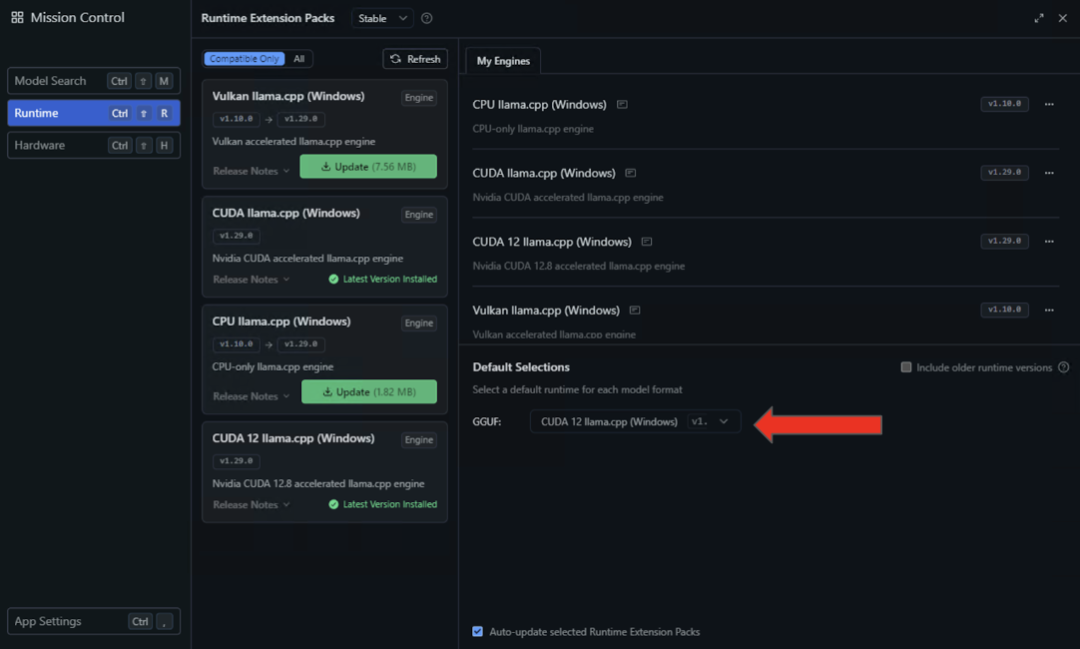
2、选择左侧面板中的运行时设置,然后在可用性列表中搜索 CUDA 12 llama.cpp(Windows)运行时。点击按钮进行下载与安装。
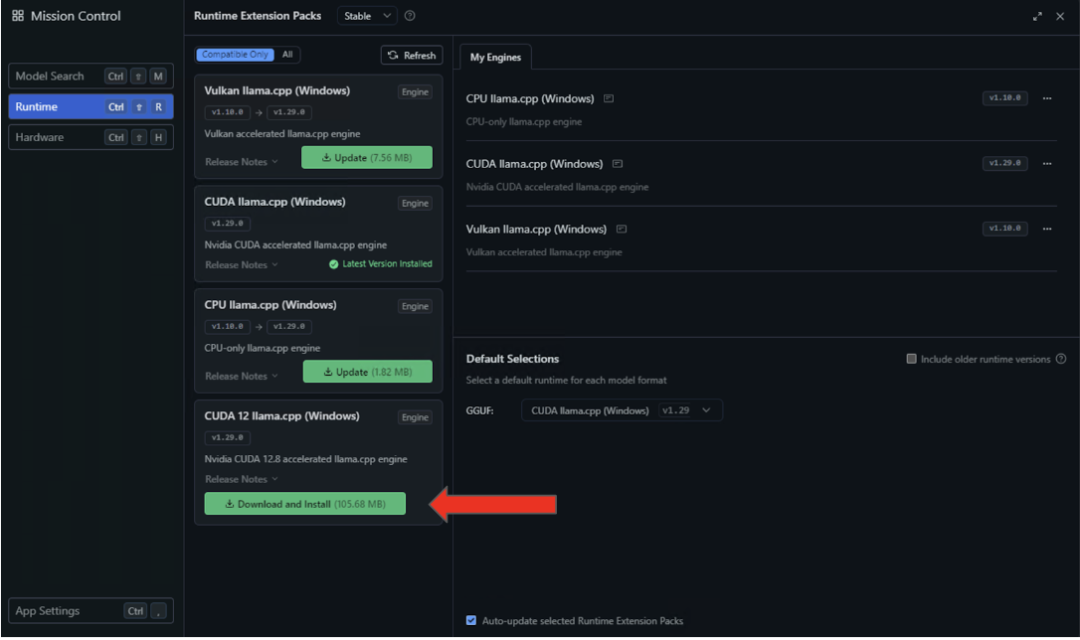
3、安装完成后,通过在“默认选择”下拉菜单中选择 CUDA 12 llama.cpp(Windows),将 LM Studio 默认配置为此运行时环境。
4、完成 CUDA 执行优化的最后步骤:在 LM Studio 中加载模型后,点击已加载模型左侧的齿轮图标进入设置菜单。

5、在展开的下拉菜单中,将“Flash Attention”功能切换为开启状态,并通过向右拖动“GPU Offload”(GPU 卸载)滑块将所有模型层转移至 GPU。
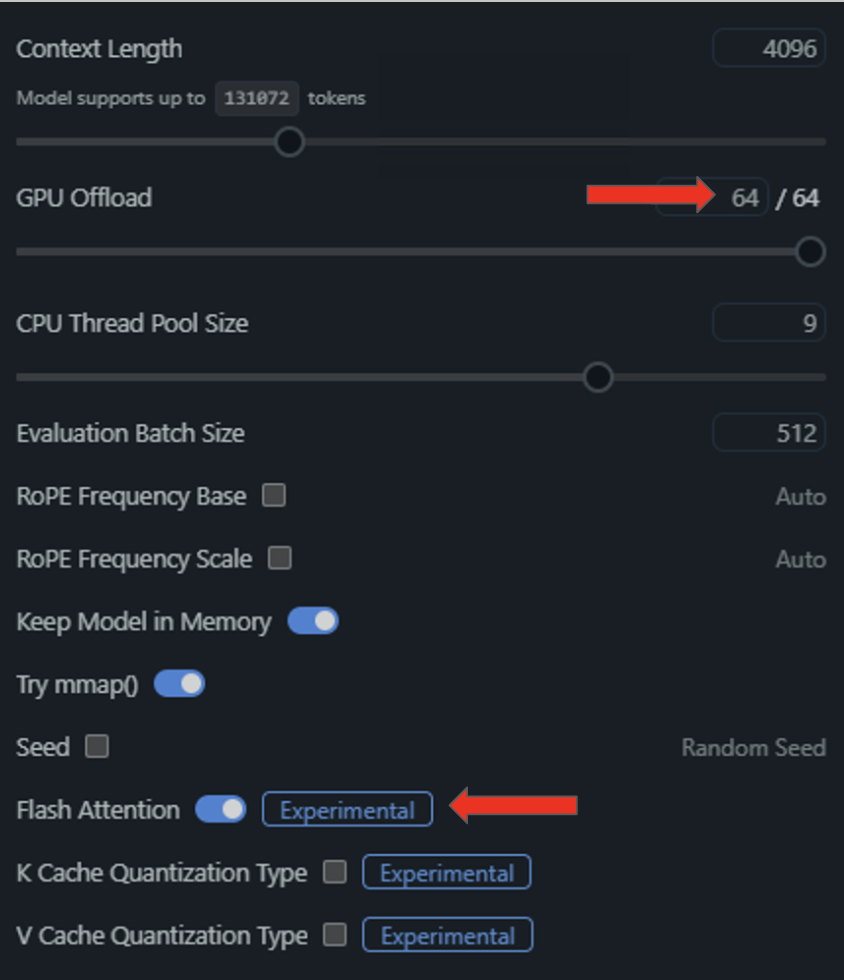
完成这些功能的启用与配置后,即可在本地设备上运行 NVIDIA GPU 推理任务了。
LM Studio 支持模型预设、多种量化格式及开发者控制项比如 tool_choice,以实现调优的推理。对于希望参与贡献的开发者,llama.cpp 的 GitHub 仓库持续积极维护,并随着社区与 NVIDIA 驱动的性能优化持续演进。
想要了解及购买英伟达NVIDIA产品,请前往iCEasy商城品牌专区:
iCEasy商城欢迎您的到来!
