
进迭时空专注于研发基于RISC-V的高性能新AI CPU,对于充分发挥CPU核的性能而言,编译器是不可或缺的一环,而在AI时代,毫无疑问向量算力将发挥越来越重要的作用。进迭时空非常重视RISC-V高性能算力生态的建设,正投入编译器自动向量化优化等多项关键技术,全面助力RISC-V的高性能发展。
RISC-V 向量设计
在现代CPU中,向量支持是算力的一个重要组成部分。1996年Intel就推出了针对多媒体应用程序设计的SIMD指令集MMX,随后又逐步引入了SSE、AVX、AVX2、AVX-512,Arm也引入了NEON指令集支持,并在armv8版本中将NEON定义为默认支持,后续又引入了长度可变的SVE。
对于新兴的RISC-V架构, 同样也有vector扩展支持。RISC-V Vector Extension(下文简称RVV)是 RISC-V 指令集架构(ISA)中的一种扩展,专门设计用于高效的向量处理。RVV 为RISC-V 指令集架构引入了强大的向量处理能力,旨在通过向量化计算提高多种应用程序的计算性能。
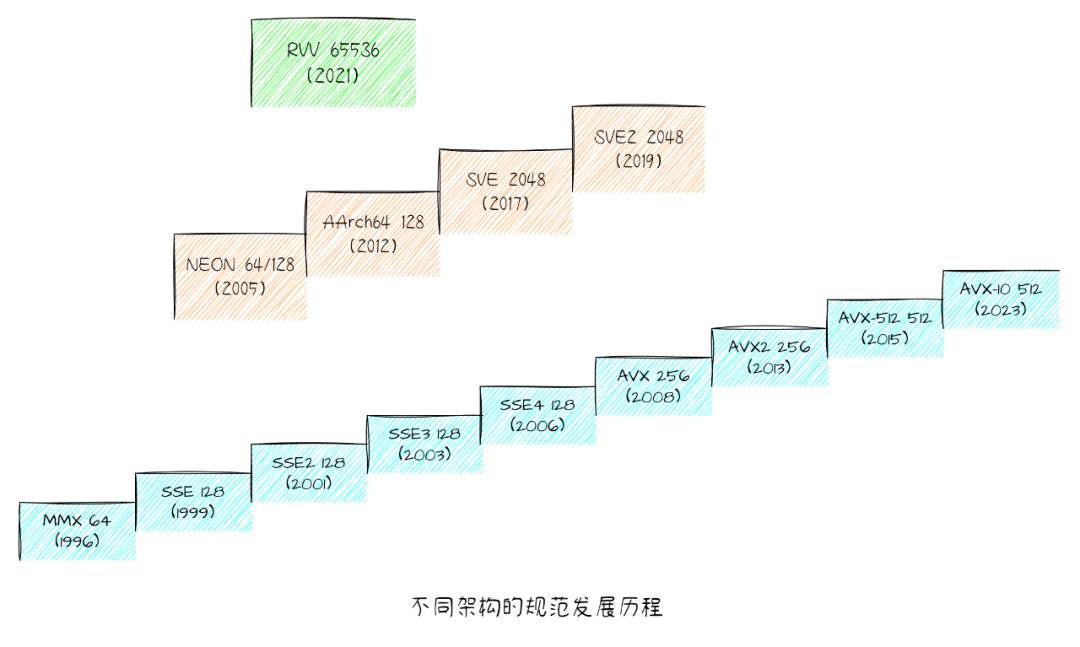
吸收了其他架构的经验,RISC-V发现传统的SIMD指令设计并不够好,不同的宽度引入不同的SIMD指令,使得整个指令集越来越庞大和复杂。RISC-V的发明人Patterson教授在《SIMD Instructions Considered Harmful》一文中阐述了这一观点。
最终RVV的设计更类似于SVE,是可变长的向量,而且非常灵活,可在运行时动态设置寄存器大小,分组,宽度,以及掩码操作等,可以做到同一份二进制文件在不同VLEN的硬件上都能充分发挥硬件性能。
其灵活的设计和易于编程的特性,使其在现代计算任务中具有明显的优势,并为未来的计算需求提供了良好的支持。随着 RISC-V 生态系统的发展,RVV 有望在更多应用中发挥重要作用。
自动向量化
如何利用向量算力,一种方式是软件开发者直接调用向量的编程接口,另一种方式是直接编写标量代码通过编译器实现自动向量化,这两种方式各有优劣,都不可或缺。
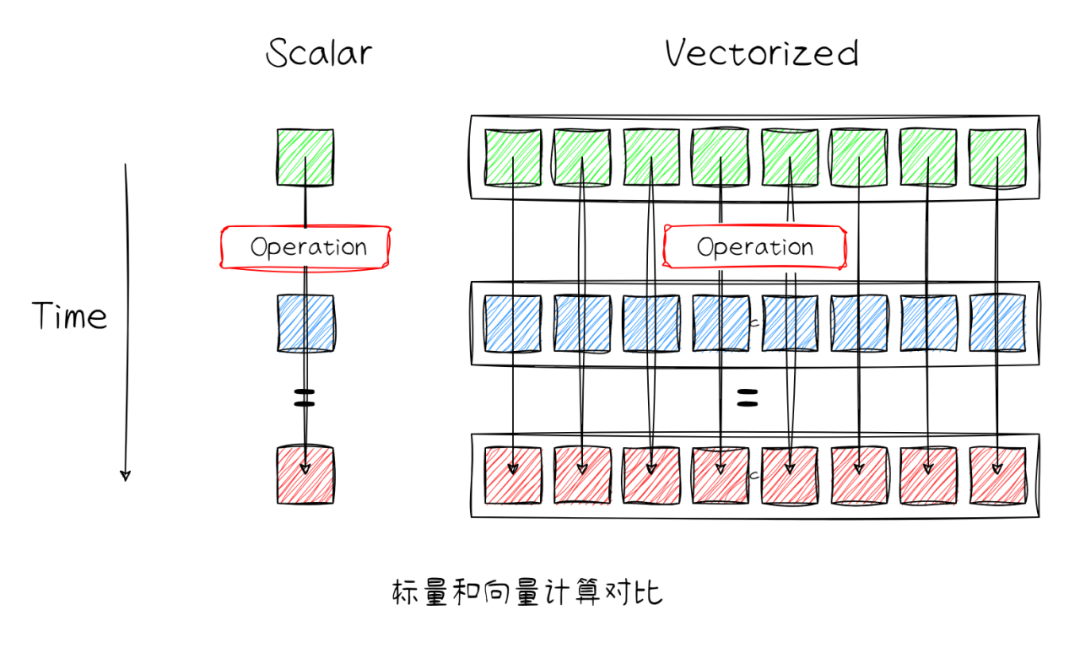
向量化(Vectorization)是一种编程和编译优化技术,自动向量化的本质是编译器识别程序中的循环或者基本块,将多个标量操作组合在一起,利用编译器数据流/控制流等分析技术自动生成SIMD/向量指令的过程,以此达到提高数据并行,加快数据计算的目的。
由于其在科学计算、图像处理、机器学习和数字信号处理等领域具有广泛的应用,使得业界对向量化这项技术一直有持续的关注和投入,主要是因为是自动向量化可以带来很多优势:
· 性能提升:自动向量化利用硬件架构提供的SIMD/Vector指令,减少了迭代循环的开销,且提高数据并行处理的能力,对计算密集或者数据规模大的场景会带来极大的性能优势。
· 降低编程的复杂性:开发者不需要手动编写复杂的向量化代码,交给编译器自动分析、优化和生成向量代码。
· 兼容性和可移植性:通过自动向量化,开发者可以编写标准的标量代码运行在不同的平台,编译器会根据目标平台特性生成可在对应平台上执行的向量代码。
自动向量化实现
自动向量化工具
目前LLVM框架下支持的自动向量化工具有 SLP Vectorize 和 Loop Vectorize。
SLP Vectorize(superword-level parallelism)
SLP向量化关注单次迭代间的向量化机会,在基本块中搜集相似的标量指令,通过将相似标量指令合并为向量指令的方式,来实现向量化。如下程序可以通过构造向量(a1, a2)和 (b1, b2),完成向量化算术运算。
void foo(int a1, int a2, int b1, int b2, int *A) {
A[0] = a1*(a1 + b1);
A[1] = a2*(a2 + b2);
A[2] = a1*(a1 + b1);
A[3] = a2*(a2 + b2);
}Loop Vectorize
循环向量化关注循环迭代间的向量化机会,将多次迭代处理的数据利用更宽的位宽寄存器存储,使其一次能够完成多次循环迭代的数据处理,此后每次循环迭代的下标步长将扩宽成SIMD的位宽/向量元素的位宽。
for (int i = 0; i < n; i++) {
A[i] = B[i] + C[i]
}
-----> Transform
for (int i = 0; i < n; i = i + step) {
// 结合tail Folding 机制 和 Loop unroll 完成自动向量化的过程
for (int j = i; j < min(n, i + step); j++) {
A[j] = B[j] + C[j];
}
}Loop Vectorize 优化介绍
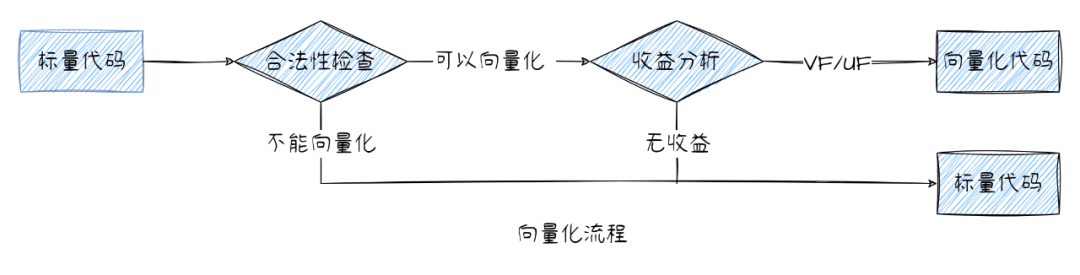
循环中的标量代码是否可以向量化,主要涉及到以下三个阶段:
- 检查当前循环是否可以向量化,对其合法性进行校验;
- 在满足合法性校验的前提下,利用代价模型分析向量化的代码是否具有收益;
- 确定向量化代码可以带来收益,完成标量代码转换为向量代码,并更新当前循环控制流。
下文会对Loop Vectorize 进行简要介绍(更多细节可以查阅文末的参考文档):
Loop Vectorize VPlan 架构介绍
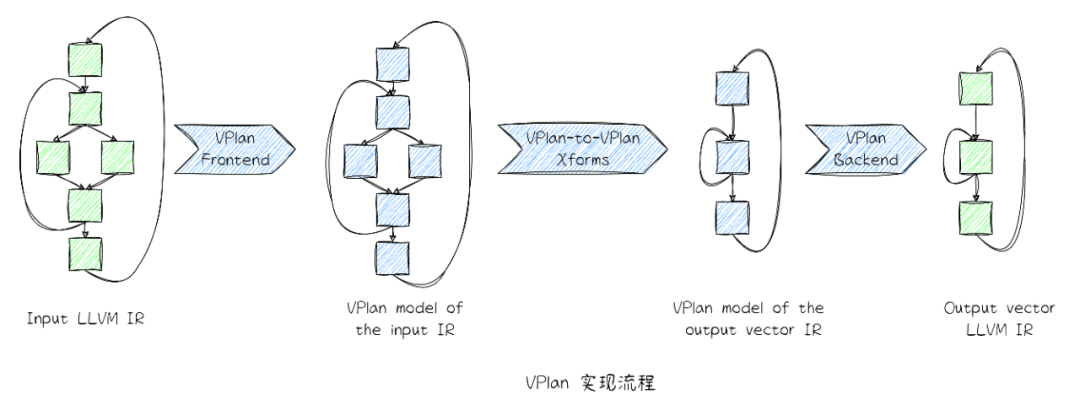
VPlan 是LLVM Loop Vectorize 基础设施的重要组成部分, 其主要是为编译器在Loop Vectorize 分析中获取到的所有向量化因子(VF)进行建模和评估,根据代价模型,选择成本最优的向量化模型,并进行转换,其存储了所有可能的向量化候选者代码,使得Loop Vectorize 实现更模块化,也增强了其可扩展性,为复杂控制流和内存访问循环提供了更多向量化的机会。
整个LLVM Loop Vectorize是基于VPlan架构实现的。其在输入和输出中间加了一层VPlan层,将IR层面的转换和分析隔离,可以有效地简化数据流的分析,仅需更新VPlan IR to Output IR 的控制流信息(增加了产生向量化的代码的机会),主要有以下流程:
Input IR to VPReciple IR:通过合法性分析 + TTI 对应的目标平台后端提供的代价模型获取最优VF,并将结果存储到VPlan中,完成首次VPlan model 的构建,此时无需更新控制流。
VPlan-to-VPlan Transform Pipeline:在获取VPlan 之后,针对一些场景做优化,例如冗余Recipe 删除、简化Vector Region 实现(循环条件或者循环归纳变量的优化)和插入EVL等。
VPRecipe IR to Output IR:利用VPTransformState中提供的信息存储和吐出Output IR,生成真正的vectorizing code,此时需要重新调整循环结构并更新控制流。
Loop Vectorize 实现方式
LLVM 在Loop Vectorize 中的实现主要有以下两种方式:Vector Length Specific 和 Vector Length Agnostic 。下文会重点讲解这两个方案的优劣势并通过如下用例展示效果。
void vp_add(int *restrict a, int *restrict b, int *restrict c, int N)
for (int i = 0; i < N; i++) {
a[i] = b[i] + c[i];
}
}Vector Length Specific (VLS)
编译器在Loop Vectorize优化阶段直接利用硬件的向量寄存器位宽进行向量化。如果当前存在尾部元素没办法填满向量寄存器,则使用标量的方式处理尾部元素。
优势:
· 目前,Loop Vectorize架构已经实现且无需特殊的 IR-Level Express。
劣势:
· 需要单独处理循环尾序。
· 没充分利用RVV Scalable的特性,其生成的二进制只能在指定的VLEN 架构上运行。
编译选项
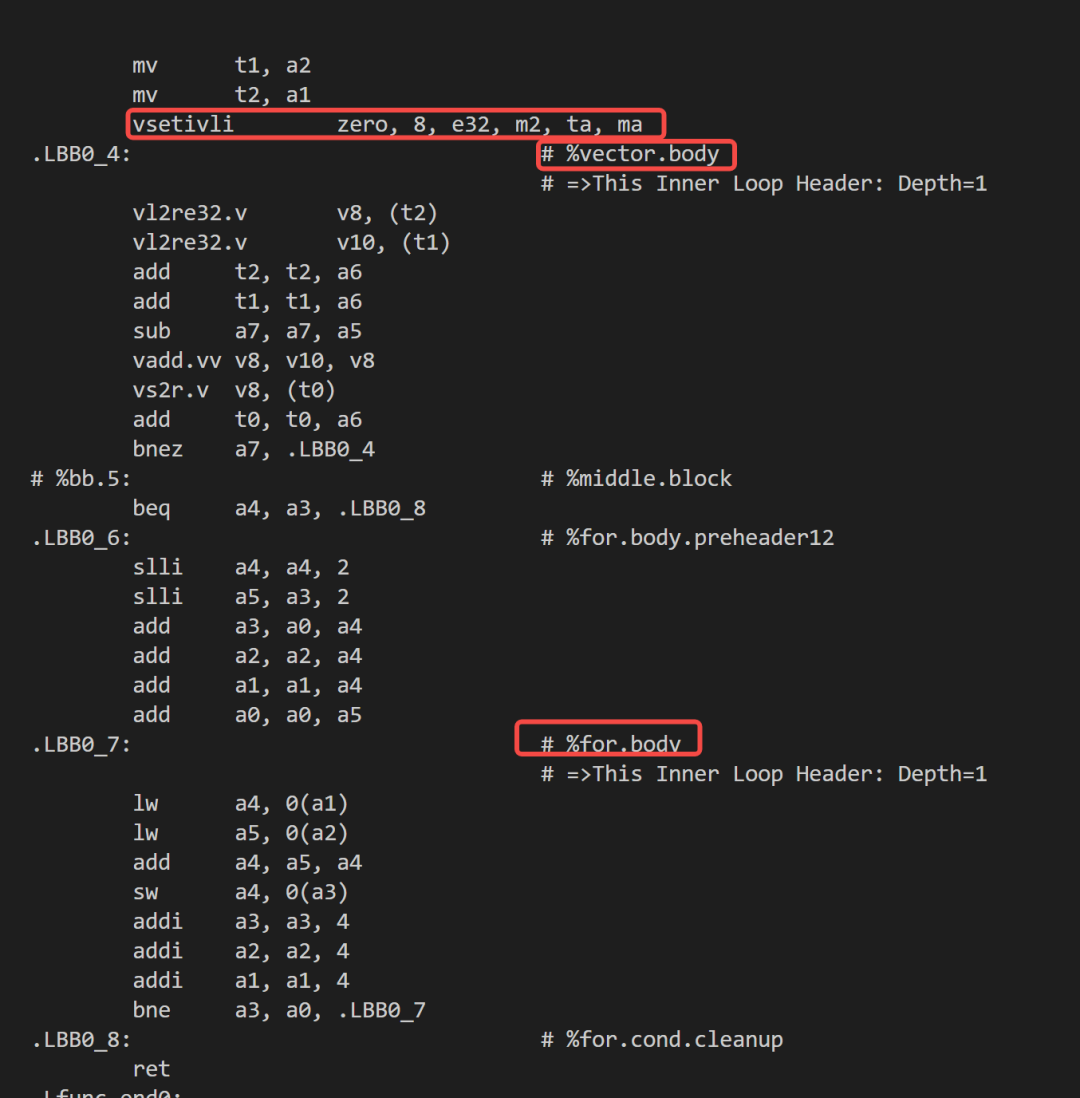
clang --target=riscv64 -march=rv64imav -mllvm -riscv-v-vector-bits-min=128 -mllvm -riscv-v-vector-bits-max=128 -O3 -S xxx.c -o xxx.s汇编效果
注:用于向量配置的 vsetivli 指令是位于向量循环 .LBB0_4 的外部。在向量循环结束后,还需要一个额外的标量循环 .LBB0_7 处理尾部元素。
Vector Length Agnostic(VLA)
最近几年,LLVM 引入了 Vector Predication IR (VP IR),其VP IR中携带的参数Mask 和 EVL(Explicit Vector Length)为独立于目标平台的各个架构提供了丰富的predicated vector instructions。当前,编译器在Loop Vectorize优化阶段的VLA 方案也是使用VP IR作为IR-Level Express完成的。编译器在循环迭代中,将所有 vector instructions 替换为predicated vector instructions,并使用EVL设置每次迭代需要处理的向量元素长度(RISC-V 架构会在后续Lowering阶段翻译成RVV vsetvli/vsetvl/vsetivli 指令)。
优势:
· 充分利用RVV 的Scalable 特性,其生成的二进制可以在任何VLEN架构上运行。
· 无需单独处理循环尾序和条件分支。
劣势:
· 需要特殊的 IR-Level Express(不过目前RVV VP的设计和慢慢趋于稳定,积极推进了Loop Vectorize在此方案的实现)。
· 所有的vector instructions都带有predicate标识,且CFG也是,这对于分支预测率比较高或者条件分支执行的概率很低的场景,可能会带来负向性能收益。
编译选项
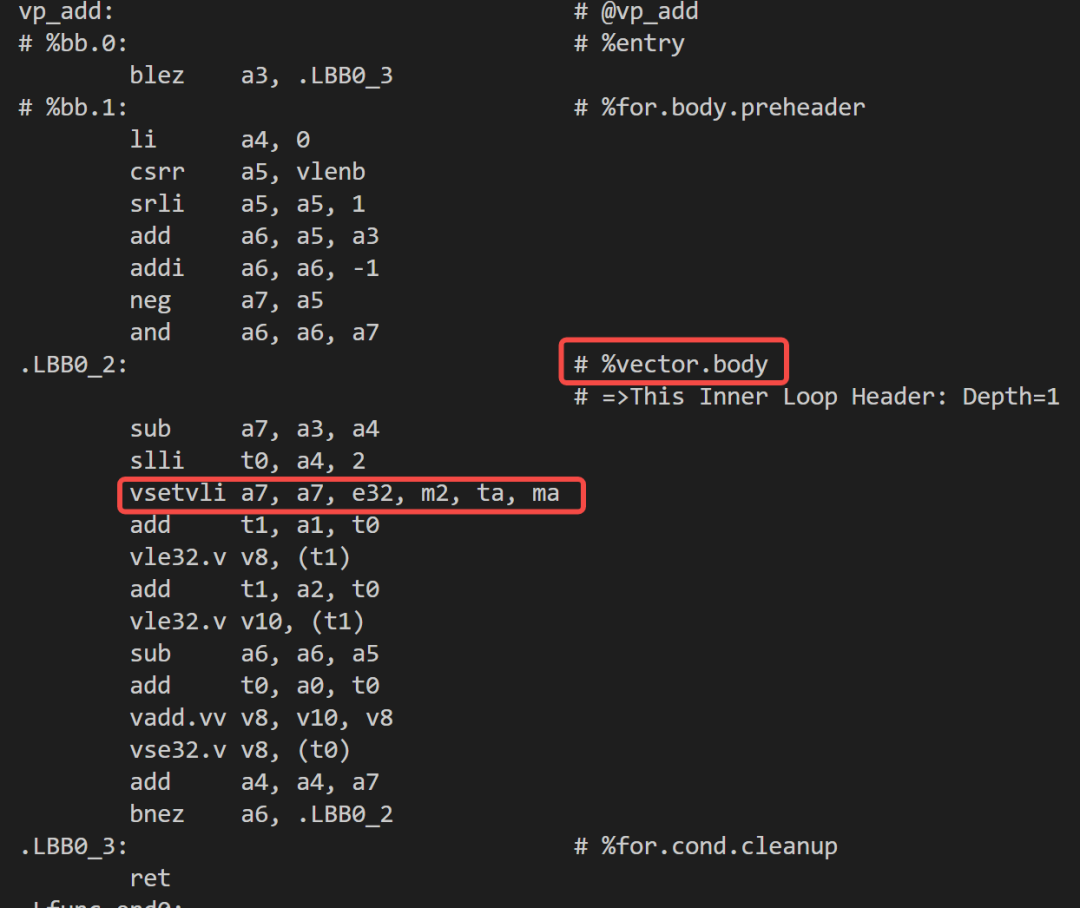
clang --target=riscv64 -march=rv64imav -mllvm -force-tail-folding-style=data-with-evl -mllvm -prefer-predicate-over-epilogue=predicate-dont-vectorize -O3 -S xxx.c -o xxx.s汇编效果
注:用于向量配置的 vsetvli 是位于向量循环.LBB0_2的内部,每次都会动态设置处理的元素个数,达到的效果是向量循环之后整个函数就结束了,无需再有额外的代码处理尾部元素。
未来的重点工作方向
进迭时空当前已经发布的K1芯片全面支持RISC-V Vector 1.0,其VLEN为256,后续也将推出具有更长VLEN的CPU核,进一步强化向量算力。从整个RISC-V生态考虑,灵活使用RVV相关特性,兼容程序在不同向量位宽配置的硬件上运行,将更有利于RISC-V向量算力的广泛应用。
目前,社区在积极投入基于VLA的开发实现上,进迭时空也在投入和跟踪社区向量化的开发贡献工作中。以下是Loop Vectorize优化中使能VLA比较关键的几个PATCH:
· https://github.com/llvm/llvm-project/pull/76172
· https://github.com/llvm/llvm-project/pull/93854
· https://github.com/llvm/llvm-project/pull/90184
· https://github.com/llvm/llvm-project/pull/110412
· https://github.com/llvm/llvm-project/pull/108351
目前,自动向量化支持还有不少待完善的地方,基于社区最新分支,进迭时空会侧重下面的一些工作,且代码会陆续开源贡献给社区。
· Loop Vectorize 优化:Recipe transform to EVLRecipe 的构建、逐步移除 Legal Cost Model,完善VPlan-based Cost Model、VPlan-to-VPlan transforms等
· RISC-V 后端代价模型完善
· Vector Predicate Lowering到后端的一些通用优化
结语
进迭时空是一家基于新一代RISC-V架构的计算生态企业,布局高性能RISC-V CPU核、AI-CPU核、AI CPU芯片、软件系统等全栈计算技术,提供端到端的计算系统解决方案。
RISC-V是一个开源架构,其成功离不开繁荣的开源生态,秉承开源理念,我们的一些工作取自开源,也要回馈开源。进迭时空将持续投入包括编译器在内的RISC-V生态建设,融入RISC-V的全球发展,携手上下游的合作伙伴一起以RISC-V架构数智未来。
参考文档
· https://www.llvm.org/docs/Proposals/VectorPredication.html
· https://llvm.org/docs/Vectorizers.html
· https://llvm.org/docs/VectorizationPlan.html
· https://zhuanlan.zhihu.com/p/13326435790
· https://www.sigarch.org/simd-instructions-considered-harmful/
· https://aijishu.com/a/1060000000024513
· https://lappweb.in2p3.fr/~paubert/ASTERICS_HPC/6-6-1-985.html
· https://llvm.org/devmtg/2018-04/slides/Caballero-Extending%20LoopVectorize%20to%20Support%20Outer%20Loop%20Vectorization%20Using%20VPlan.pdf
想要了解及购买进迭时空产品,请前往iCEasy商城品牌专区:
https://s.iceasy.com/1Pjqx1
iCEasy商城欢迎您的到来!