
 开源社区
开源社区

作者在飞腾派中使用的是 Ubuntu 系统,Ubuntu 系统自带Python 3.8.10

第一步创建一个文件夹:mkdir new_folder
第二步下载所需依赖包:pip install opencv-python
pip install onnxruntime
第三步将作者提供的代码及训练好的onnx文件及测试照片上传到Ubuntu系统中:
第四步运行代码:python3 yolov8picture.py
项目运行结果:
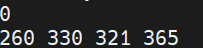
其中0表示检测到的类的ID,[260 330 321 365]表示检测结果在图片中的相对位置
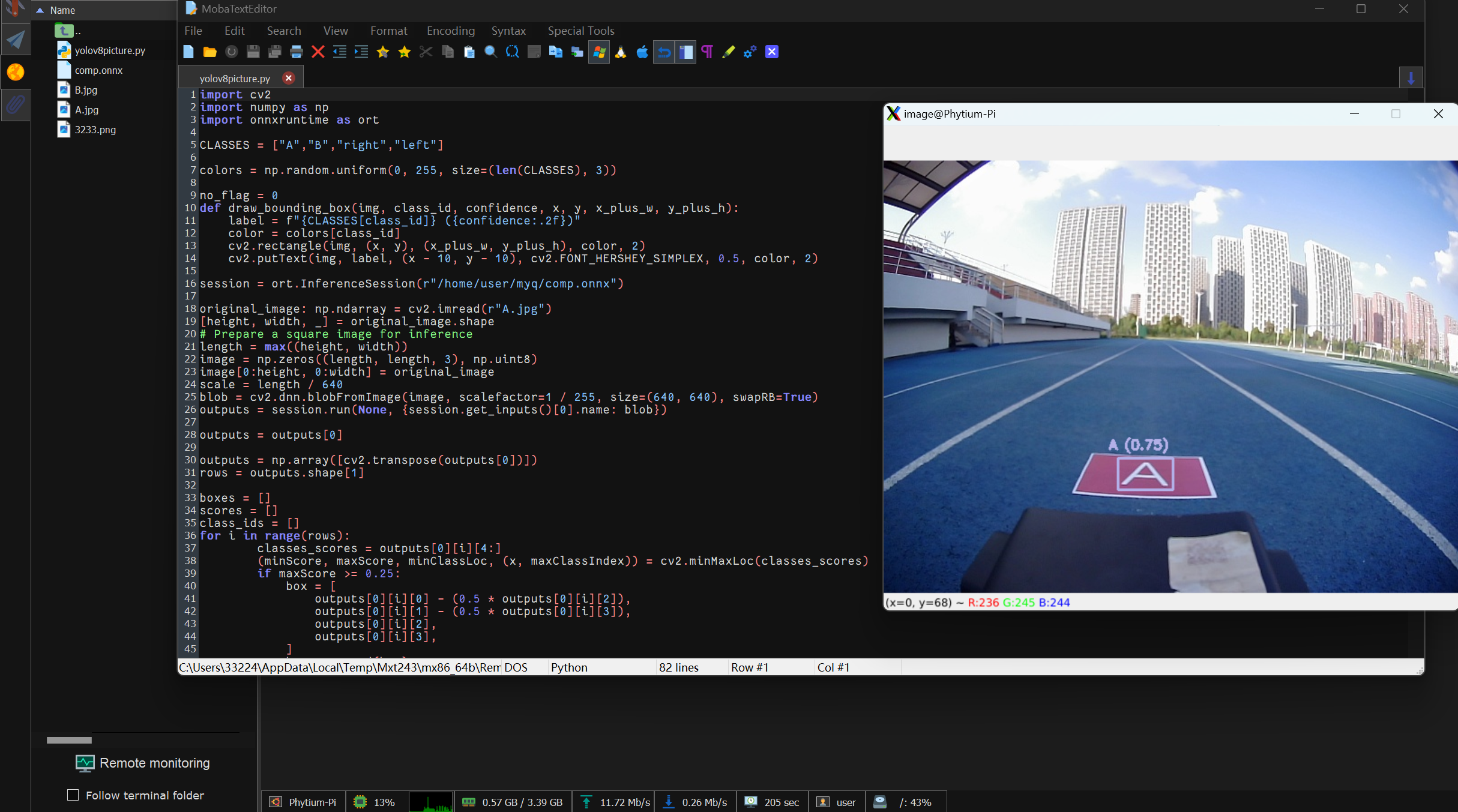
以下是目标检测代码:
import cv2
import numpy as np
import onnxruntime as ort
CLASSES = ["A","B","right","left"]
colors = np.random.uniform(0, 255, size=(len(CLASSES), 3))
no_flag = 0
def draw_bounding_box(img, class_id, confidence, x, y, x_plus_w, y_plus_h):
label = f"{CLASSES[class_id]} ({confidence:.2f})"
color = colors[class_id]
cv2.rectangle(img, (x, y), (x_plus_w, y_plus_h), color, 2)
cv2.putText(img, label, (x - 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
session = ort.InferenceSession(r"/home/user/myq/comp.onnx")
original_image: np.ndarray = cv2.imread(r"A.jpg")
[height, width, _] = original_image.shape
# Prepare a square image for inference
length = max((height, width))
image = np.zeros((length, length, 3), np.uint8)
image[0:height, 0:width] = original_image
scale = length / 640
blob = cv2.dnn.blobFromImage(image, scalefactor=1 / 255, size=(640, 640), swapRB=True)
outputs = session.run(None, {session.get_inputs()[0].name: blob})
outputs = outputs[0]
outputs = np.array([cv2.transpose(outputs[0])])
rows = outputs.shape[1]
boxes = []
scores = []
class_ids = []
for i in range(rows):
classes_scores = outputs[0][i][4:]
(minScore, maxScore, minClassLoc, (x, maxClassIndex)) = cv2.minMaxLoc(classes_scores)
if maxScore >= 0.25:
box = [
outputs[0][i][0] - (0.5 * outputs[0][i][2]),
outputs[0][i][1] - (0.5 * outputs[0][i][3]),
outputs[0][i][2],
outputs[0][i][3],
]
boxes.append(box)
scores.append(maxScore)
class_ids.append(maxClassIndex)
result_boxes = cv2.dnn.NMSBoxes(boxes, scores, 0.55, 0.45, 0.5)
detections = []
if len(result_boxes) > 0:
for i in range(len(result_boxes)):
index = result_boxes[i]
box = boxes[index]
detection = {
"class_id": class_ids[index],
"class_name": CLASSES[class_ids[index]],
"confidence": scores[index],
"box": box,
"scale": scale,
}
detections.append(detection)
draw_bounding_box(
original_image,
class_ids[index],
scores[index],
round(box[0] * scale),
round(box[1] * scale),
round((box[0] + box[2]) * scale),
round((box[1] + box[3]) * scale),
)
else : no_flag = 1
if(no_flag == 0):
print(class_ids[index])
print(round(box[0] * scale), round(box[1] * scale),round((box[0] + box[2]) * scale),round((box[1] + box[3]) * scale))
else:print("检测失败,数据集不足或该照片中无训练模型类")
cv2.imshow("image", original_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
